上次从uniprot网站用rvest提取了亚细胞定为的信息,这次还是冲uniprot用爬虫提取每个uniprotid对应的GOterm信息。
...
原理和收获
这次又尝试了两个函数html_elements和html_attr
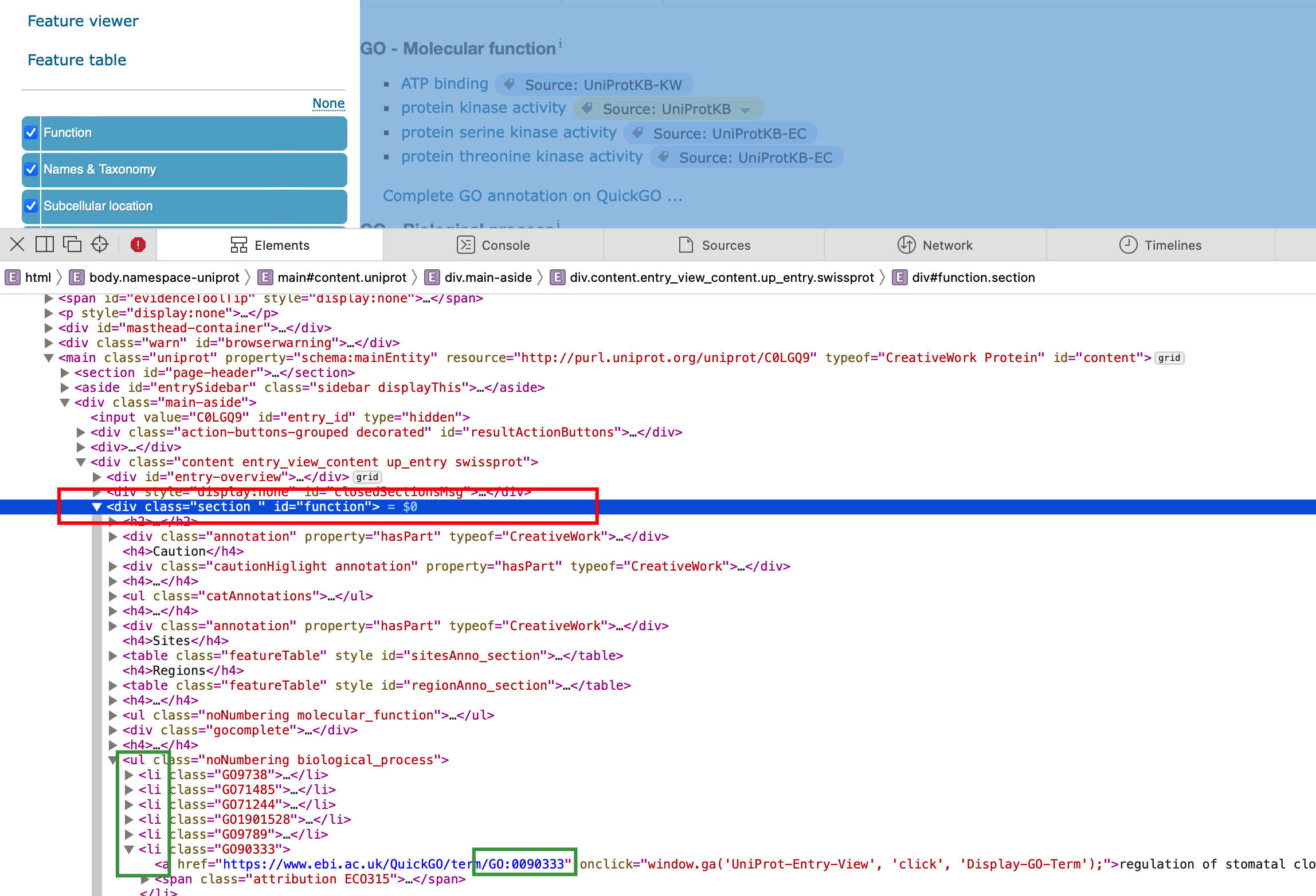
之前直接粗暴的从read_html+html_text提取一堆信息,而这次则是有条理的查找,首先我们从edge(chrome)浏览器打开GOLGQ9的信息,然后用开发者模式查看html代码,我们可以通过移动鼠标选择特定位置查看他对应网页元素,最终我们一层一层打开后发现我们需要的GO ID在
<div class = "section" id = "function">
<ul class = noBumbering xxx>
<li class="GOxxx">
<a href="http://url"...>
当然除了BP应该还有CC,MF。 所以思路就是定位到