之前在使用rvest,RCurl以及XML包编写爬虫时只是单纯的考虑到了信息提取和格式转换,没有考虑到爬虫对目标服务器的负载压力,之前也使用过暴力并行,虽然速度很快,但是对目标网站服务器负载造成了很大压力,这样既不道德,也不安全。被反爬机制检测到会封ip等。本次就实战中遇到问题解决问题做个总结。
爬虫代码
mda_knapsack_spider <- function(input_data,type = "multiple") {
#> message setting
msg_yes = green$bold$italic;
msg_no = red$bold$italic;
msg_warning = yellow$bold$italic;
message(msg_yes("---------------------------------------------------------\nStart analysis....\nGet compound information from KNApSAcK database. please wait...\n--------------------------------------------------------- "))
#> functions
#> name2cid
name2cid_fun = function(x) {
tbl <-
data.frame(
Lab.ID = x,
CAS.ID = NA,
Compound_name = NA,
Formula = NA,
mw = NA,
organism = NA,
synonyms = NA,
Judge_plant = FALSE,
InChIKey = NA,
SMILE = NA,
Species_all = NA
)
tryCatch({
ID = x
## use different user_agents.
user_agents = c(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.3 Safari/605.1.15",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/110.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0'
)
random_agent <- sample(user_agents,1)
headers = c('User_Agent' = random_agent,'Accept' = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
url <- "http://www.knapsackfamily.com/knapsack_core/result.php?sname=all&word="
# fetch the HTML content of the page
html <- RCurl::getURL(url = paste0(url,ID),header = headers,.encoding = 'UTF-8')
# parse the HTML using XML package
doc <- XML::htmlParse(html, asText = TRUE)
# find the table on the page
table <- XML::getNodeSet(doc, "//table")[[1]]
cell <- XML::xpathApply(table,"//td")
metabolite <- XML::xpathApply(table, "//td[3]/node()")[[1]]
Lab.ID <- XML::xmlValue(cell[[1]])
CAS.ID <- XML::xmlValue(cell[[2]])
Compound_name <- XML::xpathApply(table, "//td[3]/node()")[[1]] %>% XML::xmlValue()
Formula <- XML::xmlValue(cell[[4]])
mw <- XML::xmlValue(cell[[5]])
organism <- XML::xmlValue(cell[[6]])
synonyms <- XML::xpathApply(table, "//td[3]/node()") %>%
map_chr(.x = .,function(.x){ifelse(XML::xmlName(.x)=="br", NA, XML::xmlValue(.x))}) %>%
na.omit %>%
paste(.,collapse = "|")
url2 <- "http://www.knapsackfamily.com/knapsack_core/information.php?word="
html <- RCurl::getURL(url = paste0(url2,ID),header = headers)
parsed_html <- XML::htmlParse(html, asText = TRUE)
table_nodes <- XML::getNodeSet(parsed_html, "//table") # 选择所有表格节点
table <- XML::readHTMLTable(table_nodes[[2]]) # 提取第一个表格节点的表格数据
tbl = data.frame(
Lab.ID = Lab.ID,
CAS.ID = CAS.ID,
Compound_name = Compound_name,
Formula = Formula,
mw = mw,
organism = organism,
synonyms = synonyms,
Judge_plant = case_when(
str_detect(table[9,2],"Plantae") ~ TRUE,
TRUE ~ FALSE
),
InChIKey = table[5,2],
SMILE = table[7,2],
Species_all = table %>% pull(V3) %>% na.omit() %>% paste(.,collapse = "|")
)
},error = function(e) {
message(msg_no(x," no match results\n"))
})
}
multi_run_fun = function(name_list) {
name <- name_list %>% pull(knapsack_id)
p <- progressr::progressor(steps = length(name));
repeat {
b <- tryCatch({
b <- purrr::map_dfr(.x = name, .f = function(.x) {
s.time = sample(runif(n = 50,1,3) %>% round(.,digits = 2),1)
Sys.sleep(s.time);
p()
a <- name2cid_fun(x = .x)
return(a)
})
return(b)
}, error = function(e) {
message("Error occurred: ", conditionMessage(e), "\n")
NULL
})
if (!is.null(b)) {
if (nrow(b) == length(name)) {
break
} else {
missing_names <- setdiff(name, b$Lab.ID)
message(paste0("Missing ", length(missing_names), " entries, retrying..."))
name <- missing_names
}
} else {
message("Retrying...")
}
}
return(b)
}
#> run single search
if(type == 'single') {
cid_tbl <- name2cid_fun(
x = input_data
)
message(msg_yes("Done!"))
}
#> run multiple search
if(type == 'multiple') {
#> check format
if ("knapsack_id" %in% colnames(input_data) ) {
Name_clean = input_data %>%
select(knapsack_id) %>%
distinct() %>%
drop_na() %>%
mutate(order = seq(1:nrow(.)))
} else {
return();
message(msg_no('Error in input data infomation, please set the colname of kanpsack id as "knapsack_id"'))
}
#> run
with_progress({
kns_tbl = multi_run_fun(name_list = Name_clean)
})
message(msg_yes("Done!"))
return(kns_tbl)
}
}
library(RCurl)
library(XML)
library(tidyverse)
library(crayon)
library(progressr)
query <- read.csv("~/SynologyDrive/database/02.MS/KNApSAcK/KNApSAcK_MS1_db.csv")
query <-
query %>%
dplyr::select(Lab.ID,RT) %>%
setNames(c("knapsack_id","tag"))
t.start <- Sys.time()
part1 <- mda_knapsack_spider(input_data = query[1:1000,])
t.end <- Sys.time()
cat(t.end -t.start)
代码解析
首先我们去目标网站
我们在KNApSAcK网站输入C_ID后首先会出现上面页面,从页面看,主要为一个表格,那么我们只需要把这个表格提取出来,该网站无需用户登录信息,所以一般request method为GET,从下图打开开发者模式后可以看到。所以在请求的时候思路就是用RCurl::getURL函数请求网址,然后通过XML::htmlParse函数来解析网址,再通过XML::getNodeSet定位表格,用XML::xpathApply将HTML转换为包含每个条目的list。达到信息提取的目的。
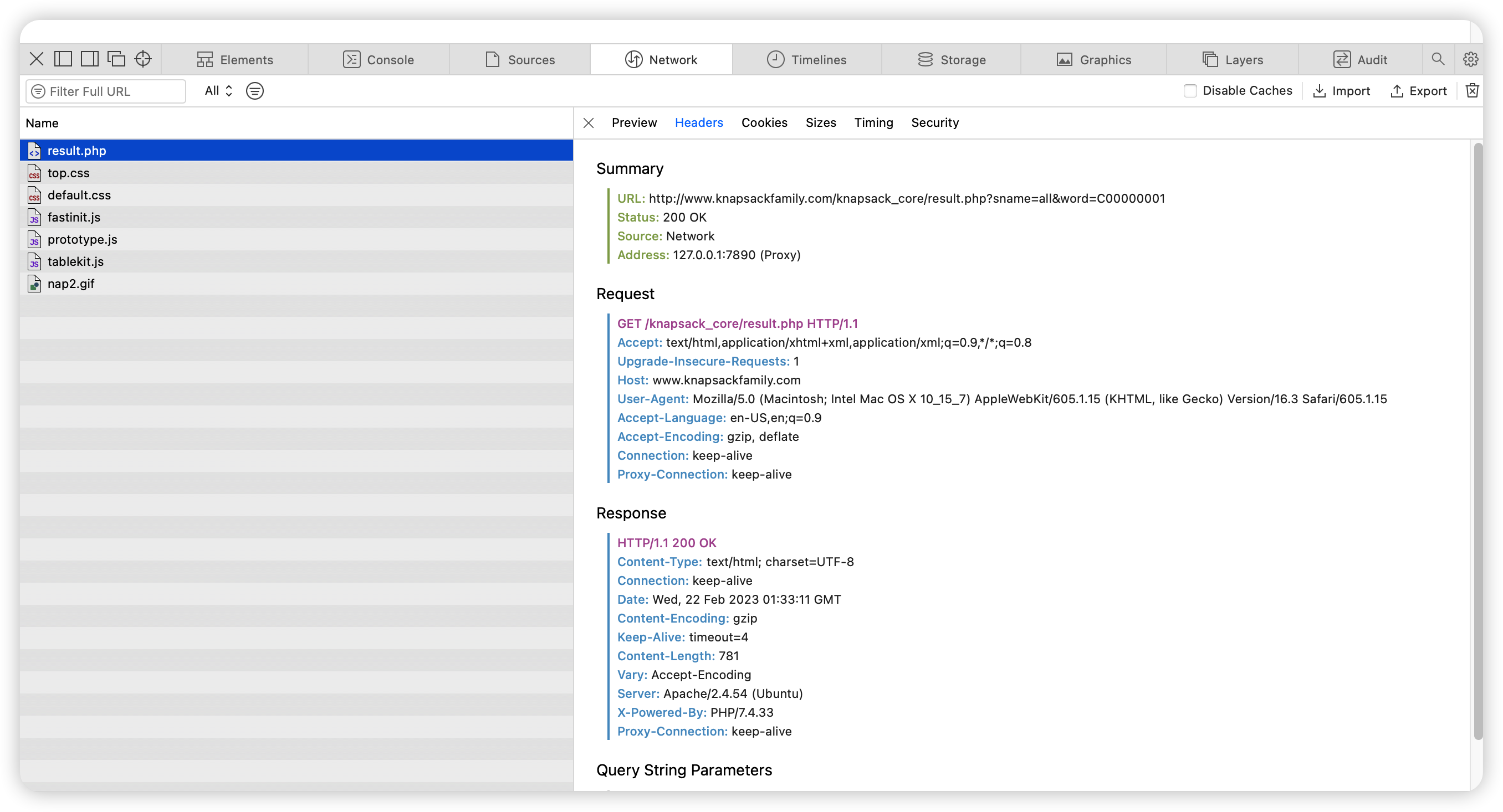
问题一:化合物名字无法和同义词区分开
我们发现KNApSAcK数据库在化合物``Metabolite这一栏会把名字和同义词放在一个cell中,用换行符隔开(回车),那么在HTML中换行符的标志是,所以我们看定位到表格后,直接输出cell`后结果如下:
cell
[[1]]
<td class="d1">
<a href="information.php?word=C00000001" target="_blank">C00000001</a>
</td>
[[2]]
<td class="d1">545-97-1</td>
[[3]]
<td class="d1">Gibberellin A1<br/>GA1</td>
[[4]]
<td class="d1">C19H24O6</td>
[[5]]
<td class="d1">348.1572885</td>
[[6]]
<td class="d1">Solanum lycopersicum</td>
attr(,"class")
[1] "XMLNodeSet"
我们发现化合物名字这个cell中的内容为<td class="d1">Gibberellin A1<br/>GA1</td>。这样就会发生一个问题,如果我们直接用XML::xmlValue函数将HTML转换为字符后所有的HTML标志都会被去掉,这样中间的<br/>也被去掉了,这样输出的结果为:
XML::xmlValue(cell[[3]])
[1] "Gibberellin A1GA1"
那么,化合物名字Gibberellin A1和它的同义词GA1就收尾相连,这在后续处理的时候是非常麻烦的。
问题一:处理方式
既然不能等到先把表格提取出来再进行格式转换,那么就直接用xpathApply把这个cell的内容提取出来转换成list,然后选择第一个作为Compound_name, 剩下的通过paste(x,collapse=”|“)将他们粘贴在一起然后用|分开。具体实现代码如下:
## 先看下这几对这个cell进行提取结果
XML::xpathApply(table, "//td[3]/node()")
[[1]]
Gibberellin A1 ## 每个元素都被提取出来,转换成字符,最后构建了个list
[[2]]
<br/> ## 换行符也被转换成了字符串
[[3]]
GA1 ## 同义词也被转换出来
attr(,"class")
[1] "XMLNodeSet"
## 那么只要用[[1]]提取上述输出结果的第一个元素然后转换为字符即可提取化合物名字
## 注意,这个list里面每个元素并不是字符串格式,而是以下格式的数据类型,需要用xmlValue函数转换为字符串
class(cell[[1]])
[1] "XMLInternalElementNode" "XMLInternalNode" "XMLAbstractNode"
##> 提取化合物名字
Compound_name <-
XML::xpathApply(table, "//td[3]/node()")[[1]] %>% ## 提取
XML::xmlValue()
##> 提取同义词
synonyms <- XML::xpathApply(table, "//td[3]/node()") %>%
map_chr(.x = .,function(.x){ifelse(XML::xmlName(.x)=="br", NA, XML::xmlValue(.x))}) %>% ## 如果html标识是<br/>,转换为NA,反之转换为字符串
na.omit %>% ## 去掉NA,也就是换行符
paste(.,collapse = "|") ## 将字符串拼接用 | 隔开。
然后将这些元素拼接到一个表格中。
问题二:缺少InChIKey及SMILE等信息
后续分类的时候我们有可能会使用pubchem数据库去再次确认这些化合物的信息,并且调取Pubchem数据库的InChIKey用于分类,因为ClassyfireR貌似对Pubchem数据库收录的InChIKey支持较好。这是可能需要化合物名字和SMILE。
这些信息在点击该网页的C_ID的链接里面:
问题二:处理方式
于是我们对这个网页信息继续进行提取,该表格比较复杂,不过最终通过对源码的解析我们也顺利抓取到了需要的信息
url2 <- "http://www.knapsackfamily.com/knapsack_core/information.php?word="
html <- RCurl::getURL(url = paste0(url2,ID),header = headers)
parsed_html <- XML::htmlParse(html, asText = TRUE)
table_nodes <- XML::getNodeSet(parsed_html, "//table") # 选择所有表格节点
table <- XML::readHTMLTable(table_nodes[[2]]) # 提取第一个表格节点的表格数据
再table_nodes 的第二个元素中,我们找到了我们需要的内容,于是继续提取,同时我们把kingdom列中的结果进行了检测,看该化合物是否来源于植物,用str_detected如果检测到Plantae我们认为该化合物在植物中存在。同时提取了物种信息,后续可能在做指定物种的非靶代谢时优先考虑这些化合物。
结果整合
这个比较简单,就是构造一个数据框,把结果填写进去。
tbl = data.frame(
Lab.ID = Lab.ID,
CAS.ID = CAS.ID,
Compound_name = Compound_name,
Formula = Formula,
mw = mw,
organism = organism,
synonyms = synonyms,
Judge_plant = case_when(
str_detect(table[9,2],"Plantae") ~ TRUE,
TRUE ~ FALSE
),
InChIKey = table[5,2],
SMILE = table[7,2],
Species_all = table %>% pull(V3) %>% na.omit() %>% paste(.,collapse = "|")
)
## 提前构造好的空df
tbl <-
data.frame(
Lab.ID = x,
CAS.ID = NA,
Compound_name = NA,
Formula = NA,
mw = NA,
organism = NA,
synonyms = NA,
Judge_plant = FALSE,
InChIKey = NA,
SMILE = NA,
Species_all = NA
)
此外在爬虫function中我们加入了tryCatch机制,如果报错了,跳过该条目继续进行下一个,这是就要去我们有个default。也就是代码开头构造的tbl,如果没有这个条目,或者网络方位失败,会跳过返回该提前构造的表格,不至于循环被打断。而且最终会提醒你哪些没有结果。
迭代运行
这里使用了purrr包的map函数进行泛函迭代,使用progressr监视脚本运行的进程。这里尝试了下对失败的结果重新爬取,但是失败了,还是需要优化。
multi_run_fun = function(name_list) {
name <- name_list %>% pull(knapsack_id) # 循环总数
p <- progressr::progressor(steps = length(name)); # progress bar
repeat {
b <- tryCatch({
b <- purrr::map_dfr(.x = name, .f = function(.x) { ## 泛函迭代
s.time = sample(runif(n = 50,1,3) %>% round(.,digits = 2),1) ##生成随机间隔时间
Sys.sleep(s.time);
p()
a <- name2cid_fun(x = .x) # 爬虫
return(a)
})
return(b)
}, error = function(e) {
message("Error occurred: ", conditionMessage(e), "\n")
NULL
})
if (!is.null(b)) {
if (nrow(b) == length(name)) {
break
} else {
missing_names <- setdiff(name, b$Lab.ID)
message(paste0("Missing ", length(missing_names), " entries, retrying..."))
name <- missing_names
}
} else {
message("Retrying...")
}
}
return(b)
}
规范化和规避反爬机制(老六必备)
规范化的爬虫代码不仅有利于我们快速批量获取信息,也能最大程度上不影响目标网站的负载,如果我们不考虑这些,直接上多线程,不设置间隔时间暴力爬取信息很可能造成网站服务器崩溃,或者被反爬机制检测到,被ban。
逻辑上就是爬虫表现的越像人类的操作越好,人类不可能每秒进行上百次的网页点击操作。我们试想一下,同时全网有1000个人在某时段访问目标网页,使用的终端,访问的内容,查找的频率都不同。那么想模拟人类的操作注意:
- ip地址不同
- 使用的终端不同
- 访问间隔不同
其中解决不同ip的问题可以使用代理池,获得稳定的代理池具有一定的难度,如果目标网站反爬机制没有那么严格的话,我感觉没必要折腾这个,特别是对于GET类型的请求。
其次通过不同终端,这个比较好解决,多开几个不同厂家的浏览器,然后打开开发人员模式在network查看User_Agent,记录下来。然后建池,在R语言汇中使用sample函数每次迭代随机选择。MAC电脑safari浏览器可以模拟不同的浏览器进行访问,这样就比较简单了,只需要在Develop => User Agent选项卡切换浏览器就可以了。
user_agents = c(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.3 Safari/605.1.15",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/110.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0'
)
random_agent <- sample(user_agents,1)
headers = c('User_Agent' = random_agent,'Accept' = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
url <- "http://www.knapsackfamily.com/knapsack_core/result.php?sname=all&word="
html <- RCurl::getURL(url = paste0(url,ID),header = headers,.encoding = 'UTF-8')
第三设置随机访问间隔,同样,我们随机生成n个1-3秒之间的随机数,用round把他控制在两位小数(没啥卵用),然后在开头用Sys.sleep()设置停顿,这样每次迭代的时等待的时间长短不一样。也就模拟了你两次点击网站的间隔也是不同的。
这样我们每个1-3秒访问一次网站,对网站的负载影响也不会太剧烈。
